
Digital transformation entails a number of pursuits, and transforming your environment when it involves extreme scale compounds that overall pursuit. When it comes to data, you’ll need to perform all manner of functions and service when creating it, processing it, storing it, and protecting it. Agencies with sizable workforces, all requiring access to large data stores in a common way but perhaps using that data to serve different purposes, are on a pursuit needing the utmost in planning and flexibility.
The beginning of this quest lies on the edge.
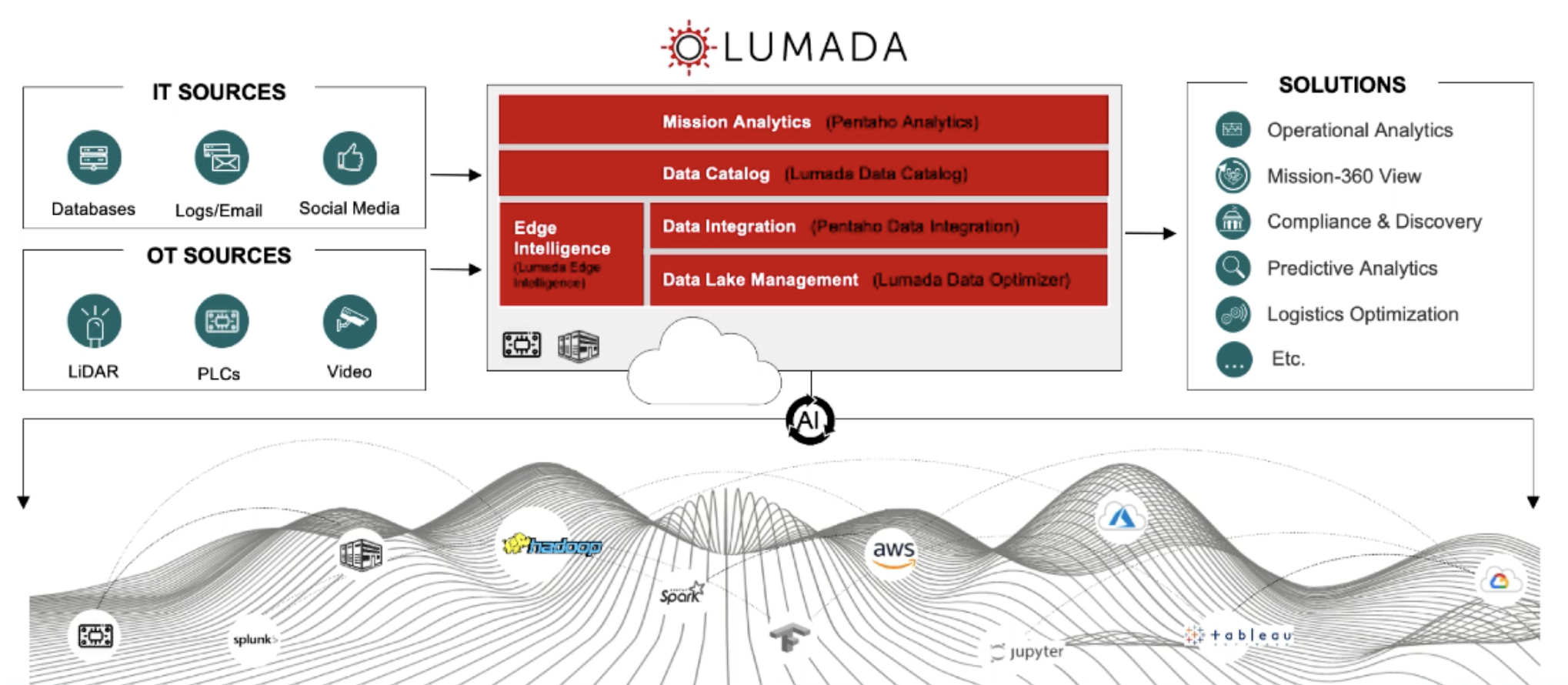
Lumada automates data management end-to-end. Our products include mission analytics with Pentaho, which is Hitachi’s leading solution for data pipeline management and analytics; Data Catalog, which is a highly automated and collaborative data discovery, inventorying, and cataloging for governance compliance and sensitive data protection; and data self-service. Data integration with Pentaho delivers containerized Lumada services for data flow orchestration and monitoring with a web-based interface and no-code data transformations. Lumada Data Optimizer for Hadoop is a policy-based solution that can improve Hadoop resource utilization with intelligent data tiering to Hitachi Content Platform. Lumada Edge Intelligence complements Lumada Data Services by supporting your DataOps and real time insights at the edge. It is certified to run on a variety of qualified Hitachi and partner hardware connecting to operational assets, equipment, and systems. The complete suite is designed to integrate into workflows that include multiple partners.
To further enhance performance and data processing in today’s mission space, Hitachi is partnering with WekaIO to offer the fastest available parallel file system to complement our highly scalable object store. Like the HCP Cloud Scale object store, the WekaIO file system is container-deployable and based on an infinitely scalable microservices architecture. We’re building optimized appliances with the WekaIO software preinstalled to increase deployment speed and help you realize the performance gains more quickly. It’s easy to get started and then to independently scale the file system and object store for the bandwidth, throughput, and capacity to meet your needs.
The next point of data management to consider is how to store so much data.
In the first generation of object storage, the primary use case was archiving data which allowed data to be stored and protected without the need to be backed up to tape. The second generation of object storage started with the acceptance of the cloud. All public cloud storage services use object storage as their primary storage and the Amazon S3 API soon became a de facto standard for writing content to the object storage. Applications could use one method to target either private clouds or public cloud services.
Today, the stage is set for the next generation in object storage. In this generation we believe object storage can redefine the purpose and value of storage and significantly enhance data management and governance. We’re committed to innovating object storage to provide superior performance and scale along with what we call Intelligent Data Management. This is the ability to define granular data management and governance policies that are enforced directly by the object storage system based on each object’s metadata. Modern use cases require multiple data transformations: moving data from place to place, complex data access protections, simple ways to provide different views of the same data based on the role of the user, and much more. This needs to be possible whether the application and object storage is based entirely on-premises, in the cloud, as a hybrid between the two, or even across multiple clouds.
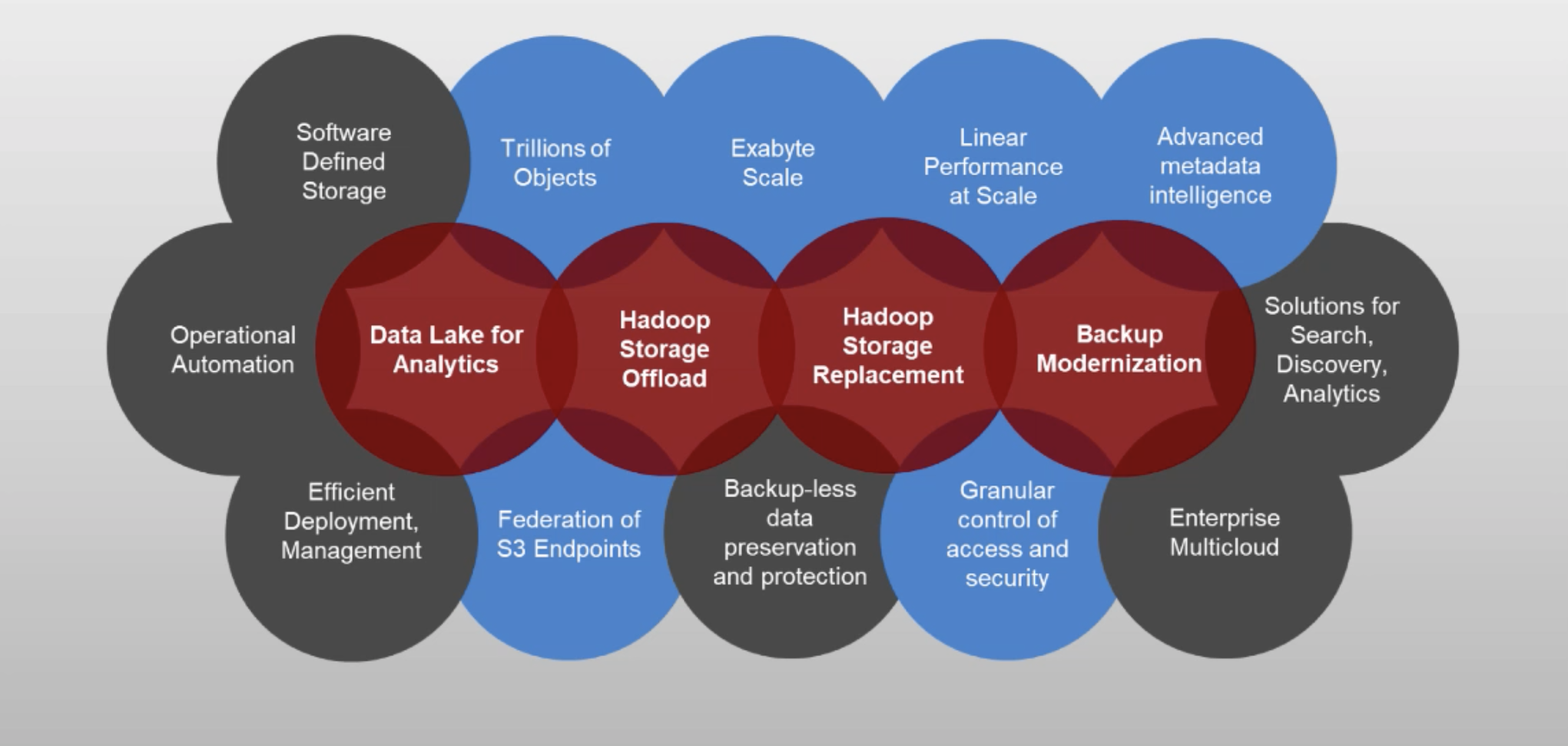
In traditional object storage architectures, the file system, along with the database management, had become performance barriers and existing metadata-based policies lack the breadth and scope required to address new requirements for Intelligent Data Services. Some key examples of such workloads are in the red circles below. The blue circles list some of the key capabilities required by modern object storage solutions to meet the requirements presented by modern day workloads. The emphasis is on developing capabilities that overcome the lack of these features in traditional designs. It’s all about updating our object stores to enable extreme scale and usability features around more extensible metadata and security.
When you think about how you extend your cloud investment it’s all about having access to the right data, at the right place, at the right time.
Whether on-premises or in the cloud, HCP for Cloud Scale can be the source OR the target. It’s the keeper of the content inventory and the intelligence in the middle. Cloud Scale provides a native industry standard S3 interface allowing easy ingestion of data from the cloud, IoT and analytics applications, as well as from traditional applications that support S3. These are examples of HCP as a storage target. With respect to HCP as a source, HCP for Cloud Scale offers the ability to federate storage, including erasure coded HTTPS nodes and S3-based storage devices, or public cloud storage services. Rather than tracking the location, movement, and placement of your content using multiple tools and application administration panels that add cost and require extra management resources, Cloud Scale alone accesses the content inventory that enables you to understand your data better and act on that knowledge. Using powerful metadata-driven policies you can place data on the right tier, decide to keep data on-site or off-site, and much more. With Hitachi Content Intelligence you can perform sophisticated search and analytics on data stored across HCP for Cloud Scale as well as your other enterprise data sources.
With respect to optimizing performance to support Tier 1 workloads, HCP for Cloud Scale provides a rich and robust set of capabilities. Core to those capabilities is enabling linear performance with scale while maintaining strong consistency. As a software-defined solution, Cloud Scale can also be deployed on your choice of hardware based on the needs of the associated workloads. Notable design aspects of Cloud Scale include a database specifically designed to deliver linear throughput in scale, an elastically scalable microservices architecture, the ability to independently scale storage and compute, and hardware-related flexibility driven by a software-defined solution.
With respect to enabling cloud scalability, HCP for Cloud Scale easily accommodates applications generating trillions of objects and associated metadata. It also offers the unique ability to linearly scale capacity and throughput. Its architecture eliminates classic database and network communication bottlenecks and was designed from the ground-up to support hundreds of nodes. Furthermore, Cloud Scale offers broad flexibility with respect to the choice of hardware along with multi-cloud support. Metadata and data services can scale independently and elastically, and storage backends can be federated to create large storage pools.
IT mission owners need to tightly manage the monetary and mission costs associated with data center operations while also increasing service levels and accelerating time to mission.
This requires infrastructure that is flexible in deployment, scale, and performance. Balancing these many success factors requires the utmost in operational flexibility. As a cloud-optimized object storage solution HCP for Cloud Scale delivers significant cost of ownership benefits based on capabilities associated with multi-cloud support, storage efficiency, built-in data durability, and data availability processes. Lastly, by relying on cost-effective HCP storage nodes, IT mission owners can flexibly scale storage on-premises or choose to burst into any S3-compatible cloud.
Today’s user environment can’t exist without offering mobile or remote access to user data based on security postures and end-to-end encryption. HCP Anywhere is a complementary application to your centralized HCP object store, and provides remote file access, file sync-and-share, and file collaboration capabilities, all the while protecting your data with the robust management features inherent to your centralized HCP object store.
HCP for Cloud Scale maintains significant cost of ownership advantages and uniquely delivers groundbreaking linear performance at scale. It further provides granular security and performance optimization while leveraging advanced metadata capabilities through a set of integrated products to enable modern intelligent data management. Overall, Lumada Data Services, together with the extensive HCP portfolio, offer unmatched flexibility and adaptability to address the broad range of data management use cases in the market.